



Antwort Is random forest bad for regression? Weitere Antworten – Is Random Forest suitable for regression
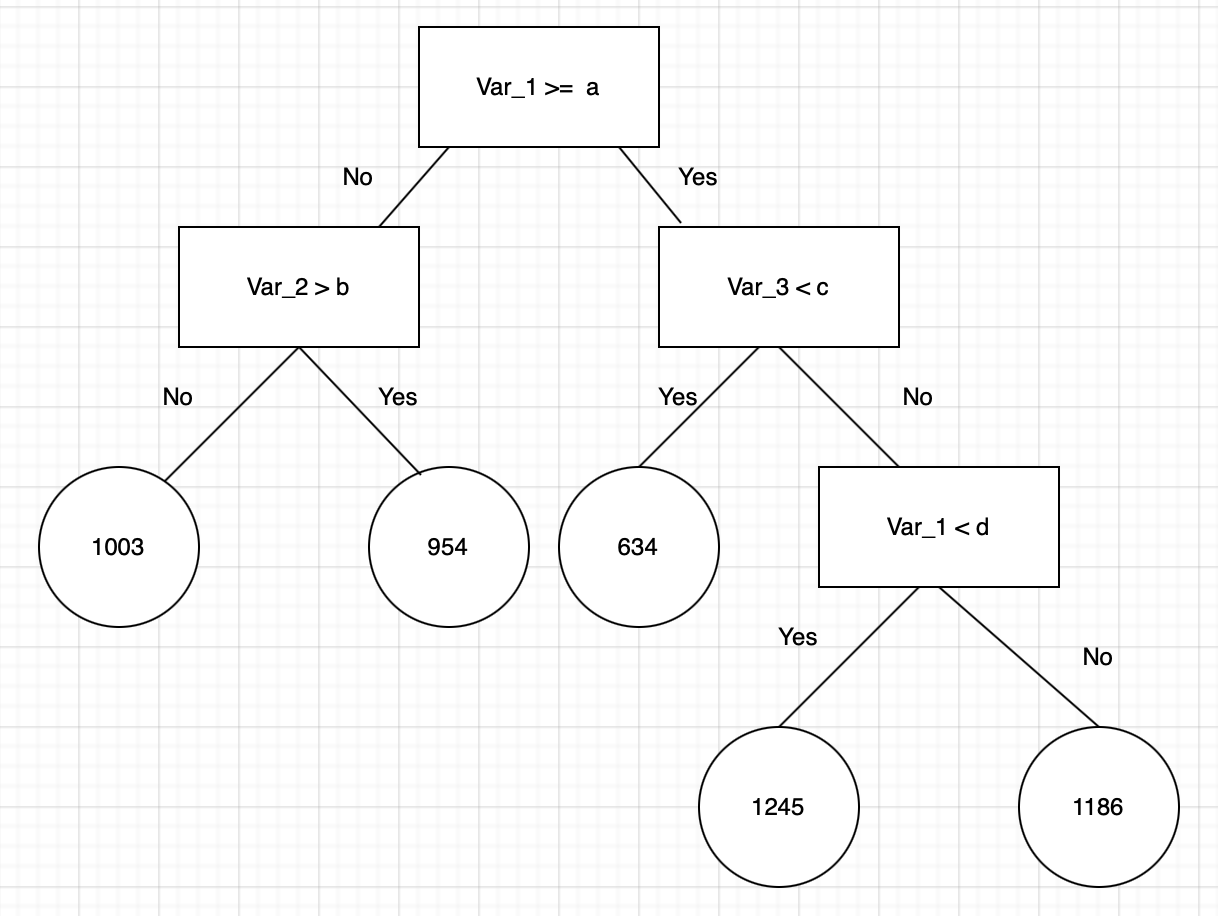
When used to estimate missing data, the Random Forest algorithm operates well in big databases and generates extremely accurate predictions. Listed below are a few advantages: It is able to carry out both classification and regression tasks.DISADVANTAGES OF RANDOM FOREST
- Random forests may result in overfitting for some datasets with noisy regression tasks.
- For data with categorical variables having a different number of levels, random forests are found to be biased in favor of those attributes with more levels.
Also, if you want your model to extrapolate to predictions for data that is outside of the bounds of your original training data, a Random Forest will not be a good choice.
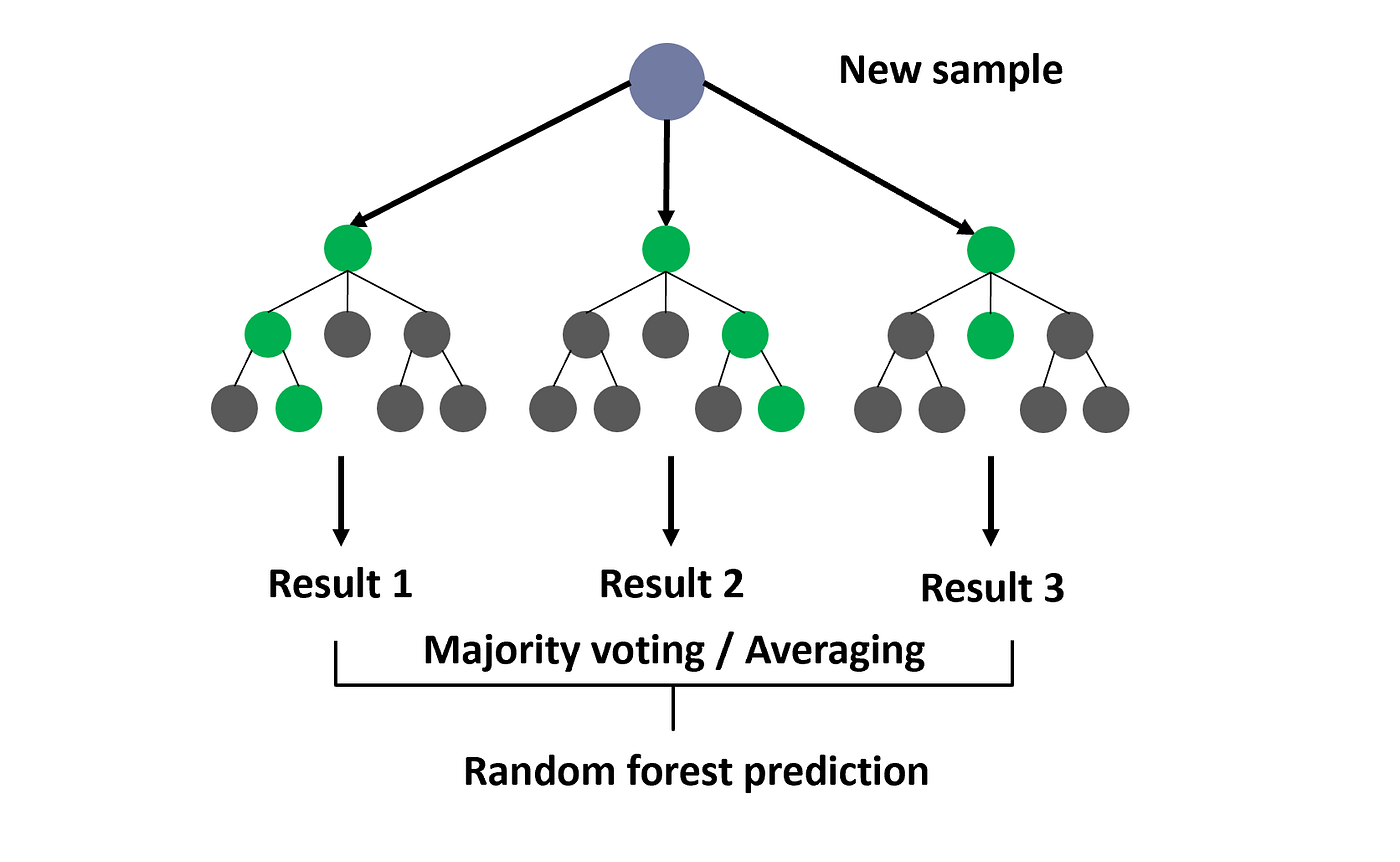
What are the weakness of random forest regression : Random Forest has several limitations. It struggles with high-cardinality categorical variables, unbalanced data, time series forecasting, variables interpretation, and is sensitive to hyperparameters . Another limitation is the decrease in classification accuracy when there are redundant variables .
Is XGBoost better than random forest for regression
Use Random Forests when you need a better balance between interpretability and accuracy. Random Forests are also good when you have large datasets with many features. Use XGBoost when your primary concern is performance and you have the resources to tune the model properly.
Why use random forest instead of linear regression : Moreover, it is less prone to overfitting due to its ability to randomly select different subsets of the data to train on and average out its results. Generally, Random Forest Regression is preferred over linear regression when predicting numerical values because it offers greater accuracy and prediction stability.
Disadvantages. Random forest is highly complex compared to decision trees, where decisions can be made by following the path of the tree. Training time is more than other models due to its complexity. Whenever it has to make a prediction, each decision tree has to generate output for the given input data.

Moreover, it is less prone to overfitting due to its ability to randomly select different subsets of the data to train on and average out its results. Generally, Random Forest Regression is preferred over linear regression when predicting numerical values because it offers greater accuracy and prediction stability.
Can decision trees be used for regression
Decision Tree is one of the most commonly used, practical approaches for supervised learning. It can be used to solve both Regression and Classification tasks with the latter being put more into practical application. It is a tree-structured classifier with three types of nodes.In general, if the relationship between your target and features is clear and easy to understand, opt for a linear regression. If you see a complex non-linear relationship, then opt for a random forest.One of the most important features of the Random Forest Algorithm is that it can handle the data set containing continuous variables, as in the case of regression, and categorical variables, as in the case of classification. It performs better for classification and regression tasks.
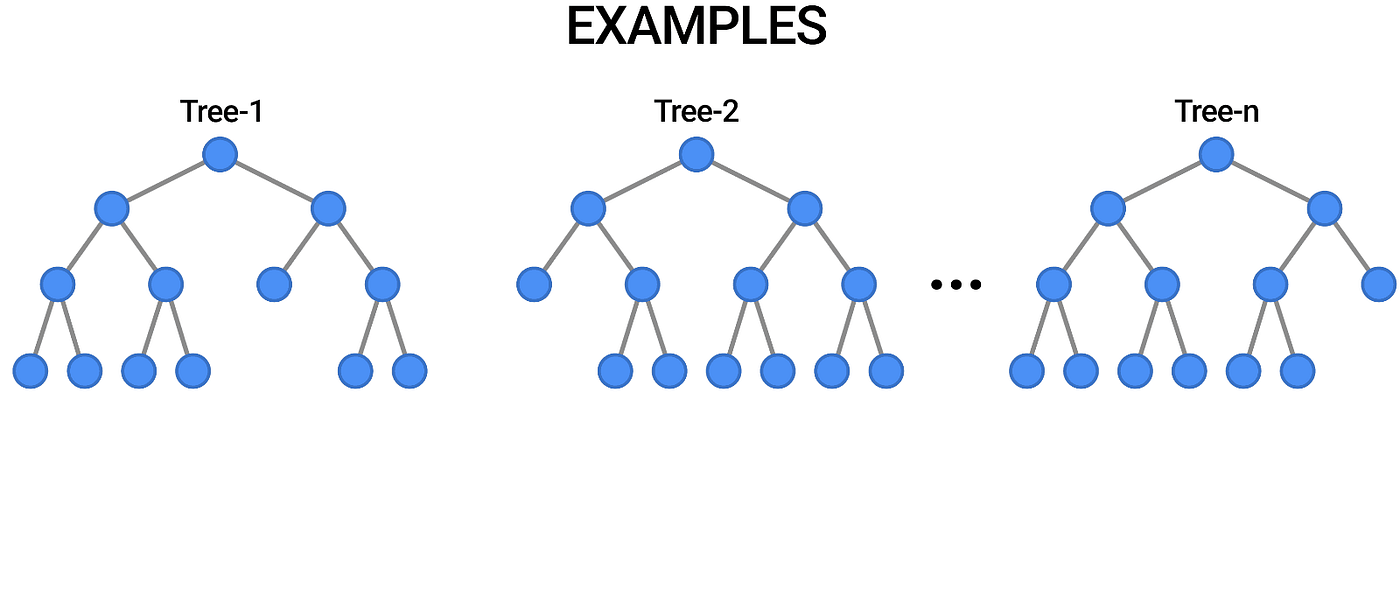
Compared to linear regression, which is a simple and interpretable method for modeling linear relationships between variables, random forests are more flexible and can model nonlinear relationships between variables.
Why Random Forest is worse than logistic regression : In general, logistic regression performs better when the number of noise variables is less than or equal to the number of explanatory variables and random forest has a higher true and false positive rate as the number of explanatory variables increases in a dataset.
What is better than a Random Forest : Gradient boosting trees can be more accurate than random forests. Because we train them to correct each other's errors, they're capable of capturing complex patterns in the data. However, if the data are noisy, the boosted trees may overfit and start modeling the noise.
Is Random Forest always better than logistic regression
In general, logistic regression performs better when the number of noise variables is less than or equal to the number of explanatory variables and random forest has a higher true and false positive rate as the number of explanatory variables increases in a dataset.
Decision Tree is one of the most commonly used, practical approaches for supervised learning. It can be used to solve both Regression and Classification tasks with the latter being put more into practical application. It is a tree-structured classifier with three types of nodes.Handling outliers: Decision trees are able to handle missing values and outliers in the data much better then a logistic regression. A decision tree is not affected by outliers because it splits the data based on the feature values.
What are the disadvantages of regression decision trees : 8 Disadvantages of Decision Trees
- Prone to Overfitting.
- Unstable to Changes in the Data.
- Unstable to Noise.
- Non-Continuous.
- Unbalanced Classes.
- Greedy Algorithm.
- Computationally Expensive on Large Datasets.
- Complex Calculations on Large Datasets.