



Antwort Is XGBoost better than random forest for regression? Weitere Antworten – Is XGBoost best for regression
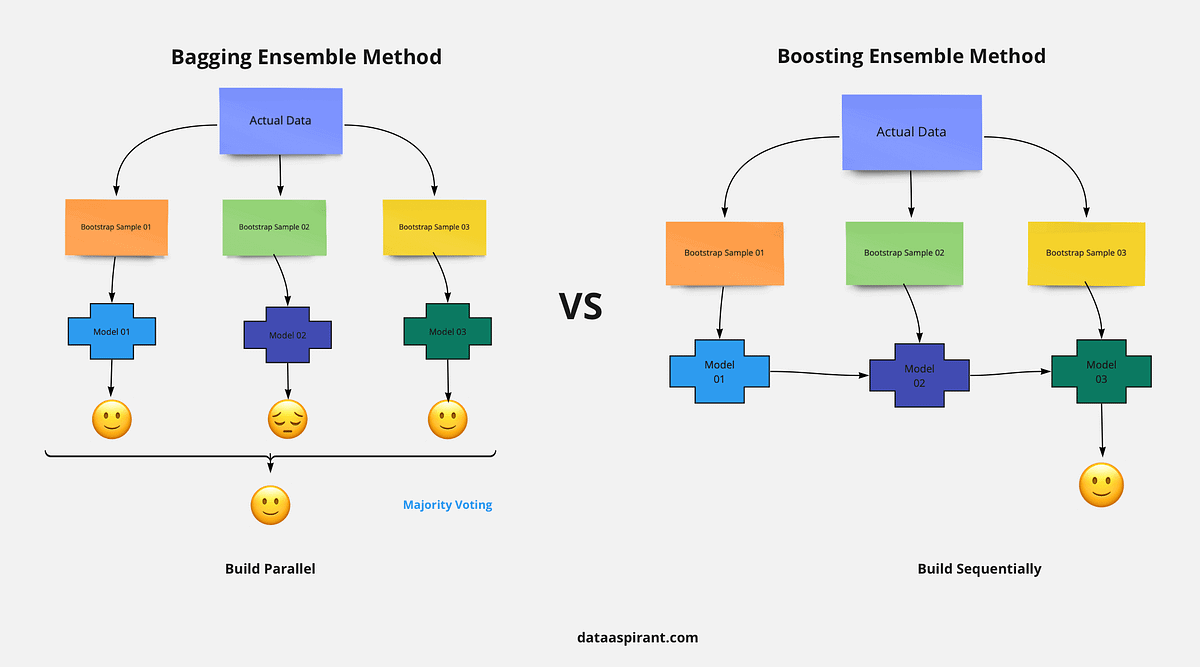
Known for its computational efficiency, feature importance analysis, and handling of missing values, XGBoost is widely used for tasks such as regression, classification, and ranking.Random Forests are also good when you have large datasets with many features. Use XGBoost when your primary concern is performance and you have the resources to tune the model properly. XGBoost is also effective when you have a mix of categorical and numerical features, and when you have a large volume of data.Gradient boosting trees can be more accurate than random forests. Because we train them to correct each other's errors, they're capable of capturing complex patterns in the data.
What is the alternative to XGBoost for regression : Paid & Free Alternatives to XGBoost
- Weka.
- Google Cloud TPU.
- scikit-learn.
- SAP HANA Cloud.
- Phrase Localization Platform.
- Vertex AI.
- SAS Viya.
- MLlib.
When should you not use XGBoost
In terms of dataset size problems, XGBoost is not suitable when you have very small training sets ( less than 100 training examples) or when the number of training examples is significantly smaller than the number of features being used for training.
Which algorithm is best for regression problem : List of regression algorithms in Machine Learning
- 1) Linear Regression. It is one of the most-used regression algorithms in Machine Learning.
- 2) Ridge Regression.
- 3) Neural Network Regression.
- 4) Lasso Regression.
- 5) Decision Tree Regression.
- 6) Random Forest.
- 7) KNN Model.
- 8) Support Vector Machines (SVM)
XGBoost, with its efficient regularization, parallel processing, and handling of sparse data, shines in diverse applications. Random Forest, a robust ensemble learner, excels in reducing overfitting and offers flexibility in various domains.

Disadvantages: XGBoost is a complex algorithm and can be difficult to interpret. XGBoost can be slow to train due to its many hyperparameters. XGBoost can be prone to overfitting if not properly tuned.
Why Random Forest is not good for regression
In other words, in a regression problem, the range of predictions a Random Forest can make is bound by the highest and lowest labels in the training data. This behavior becomes problematic in situations where the training and prediction inputs differ in their range and/or distributions.One of the biggest advantages of random forest is its versatility. It can be used for both regression and classification tasks, and it's also easy to view the relative importance it assigns to the input features.It has been replaced by reg:squarederror , and has always meant minimizing the squared error, just as in linear regression. So xgboost will generally fit training data much better than linear regression, but that also means it is prone to overfitting, and it is less easily interpreted.
However, XGBoost also has some limitations. It can be computationally expensive and time-consuming to train, especially with large datasets. Furthermore, the interpretability of XGBoost models can be challenging, making it difficult to understand the underlying factors driving the predictions.
What is the most accurate regression : If the true model is linear, then linear regression will be the most accurate, for appropriate definition of what is accurate.
What is the most common method used in regression model : Linear regression models often use a least-squares approach to determine the line of best fit. The least-squares technique is determined by minimizing the sum of squares created by a mathematical function.
Why use XGBoost over random forest
Scalability: XGBoost is generally designed for scalability and efficiency. Its gradient boosting approach builds trees sequentially, focusing on areas of error, which can be more efficient than Random Forest's bagging approach of training numerous independent trees.
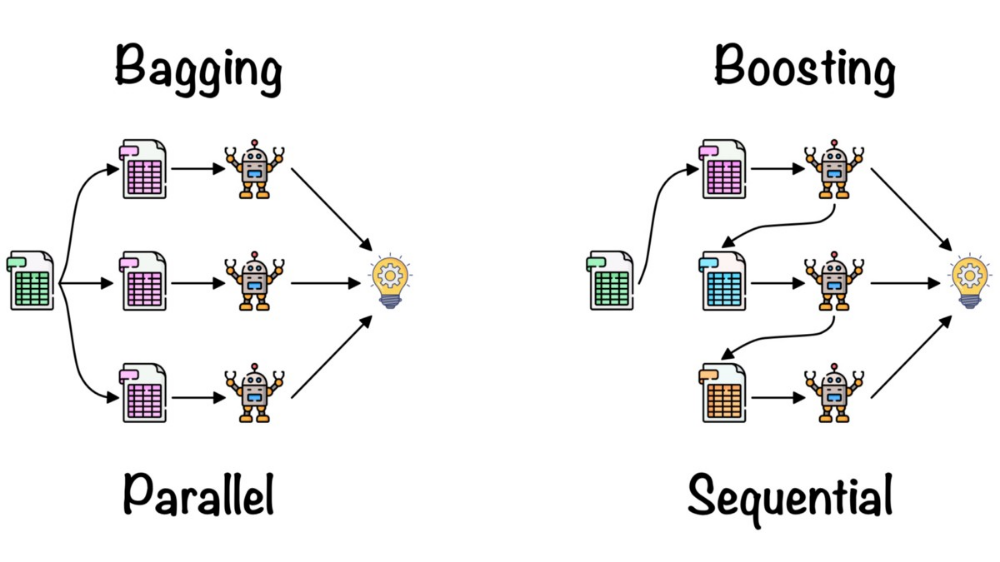
So xgboost will generally fit training data much better than linear regression, but that also means it is prone to overfitting, and it is less easily interpreted. Either one may end up being better, depending on your data and your needs.Random Forest has several limitations. It struggles with high-cardinality categorical variables, unbalanced data, time series forecasting, variables interpretation, and is sensitive to hyperparameters . Another limitation is the decrease in classification accuracy when there are redundant variables .
When should you not use random forest : Also, if you want your model to extrapolate to predictions for data that is outside of the bounds of your original training data, a Random Forest will not be a good choice.