



Antwort What is the difference between random forest and XGBoost regression? Weitere Antworten – Is XGBoost better than Random Forest for regression
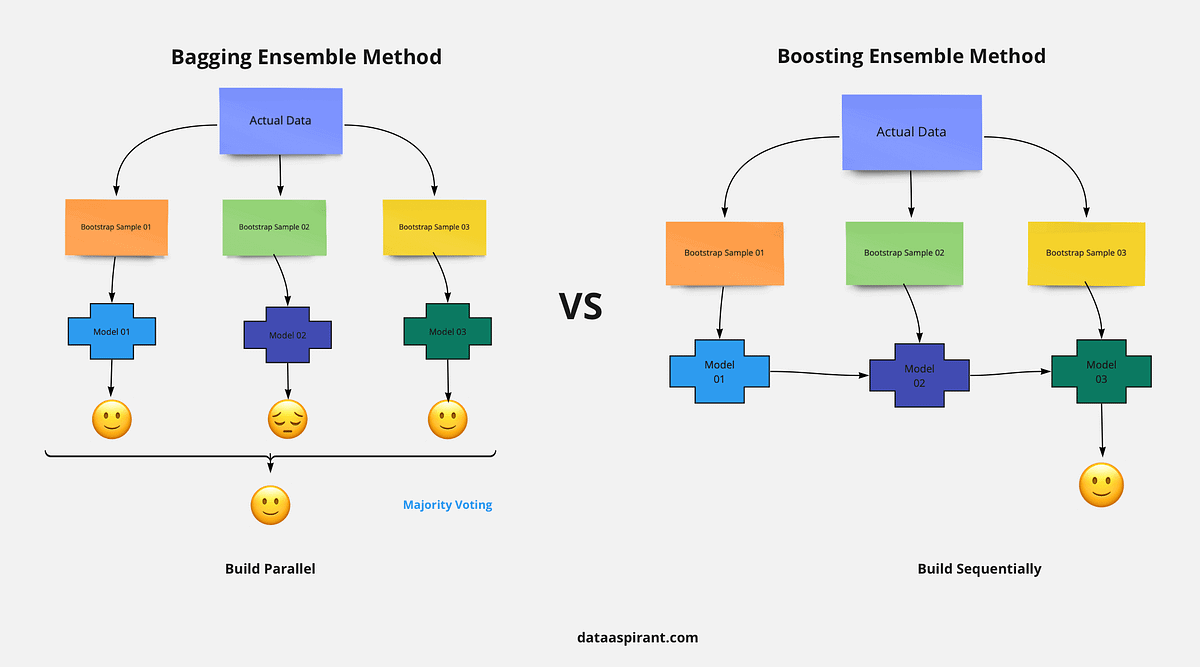
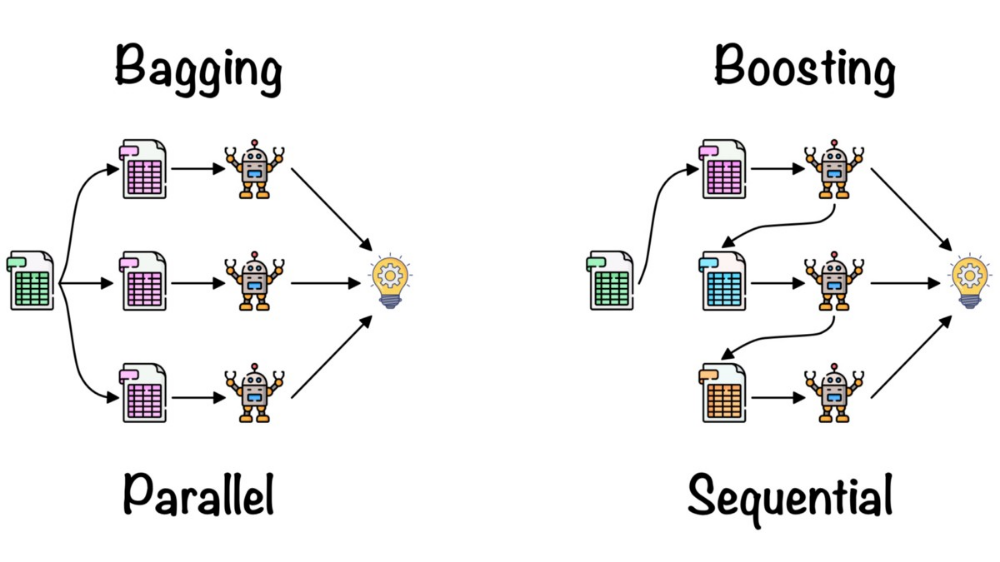
Use Random Forests when you need a better balance between interpretability and accuracy. Random Forests are also good when you have large datasets with many features. Use XGBoost when your primary concern is performance and you have the resources to tune the model properly.XGBoost, with its efficient regularization, parallel processing, and handling of sparse data, shines in diverse applications. Random Forest, a robust ensemble learner, excels in reducing overfitting and offers flexibility in various domains.XGBoost is a supervised machine learning method for classification and regression and is used by the Train Using AutoML tool.

What is the alternative to XGBoost for regression : Paid & Free Alternatives to XGBoost
- Weka.
- Google Cloud TPU.
- scikit-learn.
- SAP HANA Cloud.
- Phrase Localization Platform.
- Vertex AI.
- SAS Viya.
- MLlib.
Why does XGBoost work better than random forest
A model whose parameters adjust itself iteratively (XGBoost) will learn better from streaming data than one with a fixed set of parameters for the entire ensemble (Random Forest). The XGBoost model performs better than RF when we have a class imbalance.
Is XGBoost best for regression : Known for its computational efficiency, feature importance analysis, and handling of missing values, XGBoost is widely used for tasks such as regression, classification, and ranking.
In terms of dataset size problems, XGBoost is not suitable when you have very small training sets ( less than 100 training examples) or when the number of training examples is significantly smaller than the number of features being used for training.
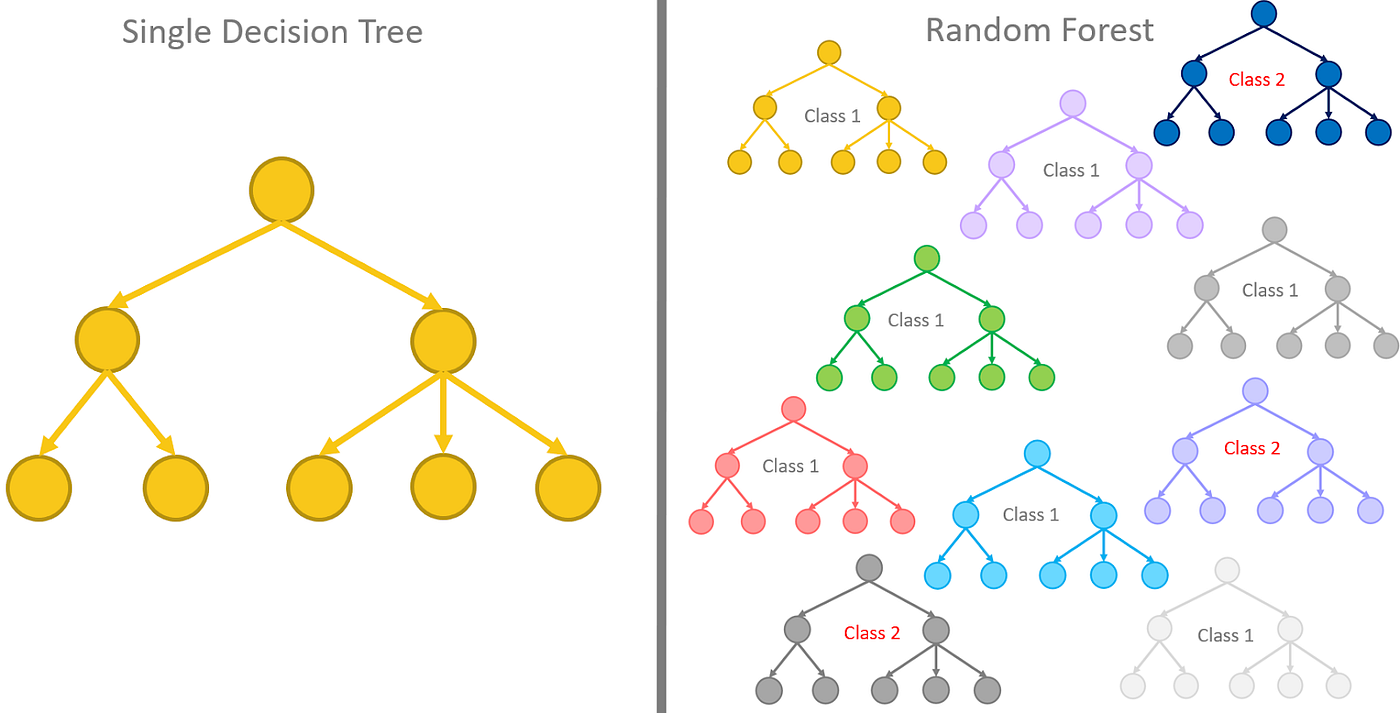
XGBoost is normally used to train gradient-boosted decision trees and other gradient boosted models. Random Forests use the same model representation and inference, as gradient-boosted decision trees, but a different training algorithm.
Can I use XGBoost for regression
Known for its computational efficiency, feature importance analysis, and handling of missing values, XGBoost is widely used for tasks such as regression, classification, and ranking.Disadvantages: XGBoost is a complex algorithm and can be difficult to interpret. XGBoost can be slow to train due to its many hyperparameters. XGBoost can be prone to overfitting if not properly tuned.They are easy to train and basically require a single hyperparameter: the number of trees. In the XGBoost Random Forest implementation, n_estimators refers to the number of trees you want to build. Higher values of n_estimators create more trees, which can lead to better performance.
XGBoost Model Benefits and Attributes
Efficiency: It is designed to be computationally efficient and can quickly train models on large datasets. Flexibility: It supports a variety of data types and objectives, including regression, classification, and ranking problems.
Is random forest a type of regression : What Is Random Forest Regression Random forest regression is a supervised learning algorithm and bagging technique that uses an ensemble learning method for regression in machine learning. The trees in random forests run in parallel, meaning there is no interaction between these trees while building the trees.
Why use XGBoost for regression : The two main reasons to use XGBoost are execution speed and model performance. XGBoost dominates structured or tabular datasets on classification and regression predictive modeling problems. The evidence is that it is the go-to algorithm for competition winners on the Kaggle competitive data science platform.
Why use XGBoost over random forest
Scalability: XGBoost is generally designed for scalability and efficiency. Its gradient boosting approach builds trees sequentially, focusing on areas of error, which can be more efficient than Random Forest's bagging approach of training numerous independent trees.

Random Forest, with its simplicity and parallel computation, is ideal for quick model development and when dealing with large datasets, whereas XGBoost, with its sequential tree building and regularization, excels in achieving higher accuracy, especially in scenarios where overfitting is a concern.Random forest is a powerful machine-learning technique that has the potential to yield better results than linear regression. It is an ensemble of decision trees, which are much more powerful at capturing non-linear relationships between features and target variables than linear models.
Can XGBoost be used for regression : Conclusion. In conclusion, XGBoost is an extensively used framework for regression problems. Its ability to handle complex datasets, as well as its efficient gradient boosting, makes it ideal for regression models that predict continuous numerical values properly.