



Antwort Why does XGBoost work better than random forest? Weitere Antworten – Why does XGBoost perform better than Random Forest
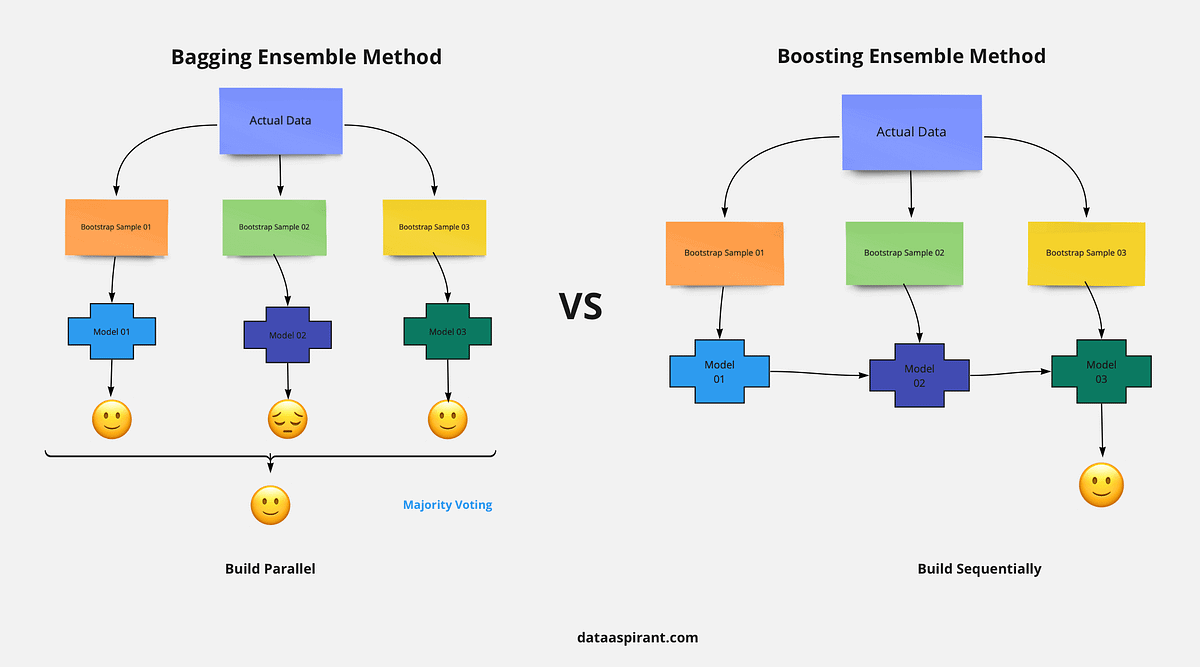
A model whose parameters adjust itself iteratively (XGBoost) will learn better from streaming data than one with a fixed set of parameters for the entire ensemble (Random Forest). The XGBoost model performs better than RF when we have a class imbalance.Gradient boosting has several advantages over random forests. They are more accurate and powerful, since they use gradient descent and residuals to optimize the ensemble and reduce the bias. They are also more flexible, since they can use any differentiable loss function or regularization technique to fit the data.Benefits. High performance: XGBoost consistently achieves state-of-the-art results in classification and regression tasks. Scalability: XGBoost efficiently uses memory and computation resources, making it suitable for large-scale problems. Regularization: Built-in regularization terms help prevent overfitting.
What are the advantages of XGBoost classification : XGBoost Benefits and Attributes
Efficiency: It is designed to be computationally efficient and can quickly train models on large datasets. Flexibility: It supports a variety of data types and objectives, including regression, classification, and ranking problems.
What is faster Random Forest or XGBoost
Though XGBoost is noted for better performance and high speed, these hyperparameters always stop developers from looking into this algorithm. Hyperparameters are not needed in Random Forest and developers can easily understand and visualize Random Forest algorithm with few parameters present in the data.
What are the disadvantages of XGBoost : Disadvantages of XGBoost:
Overfitting: XGBoost can be prone to overfitting, especially when trained on small datasets or when too many trees are used in the model. Hyperparameter Tuning: XGBoost has many hyperparameters that can be adjusted, making it important to properly tune the parameters to optimize performance.
However, XGBoost also has some limitations. It can be computationally expensive and time-consuming to train, especially with large datasets. Furthermore, the interpretability of XGBoost models can be challenging, making it difficult to understand the underlying factors driving the predictions.
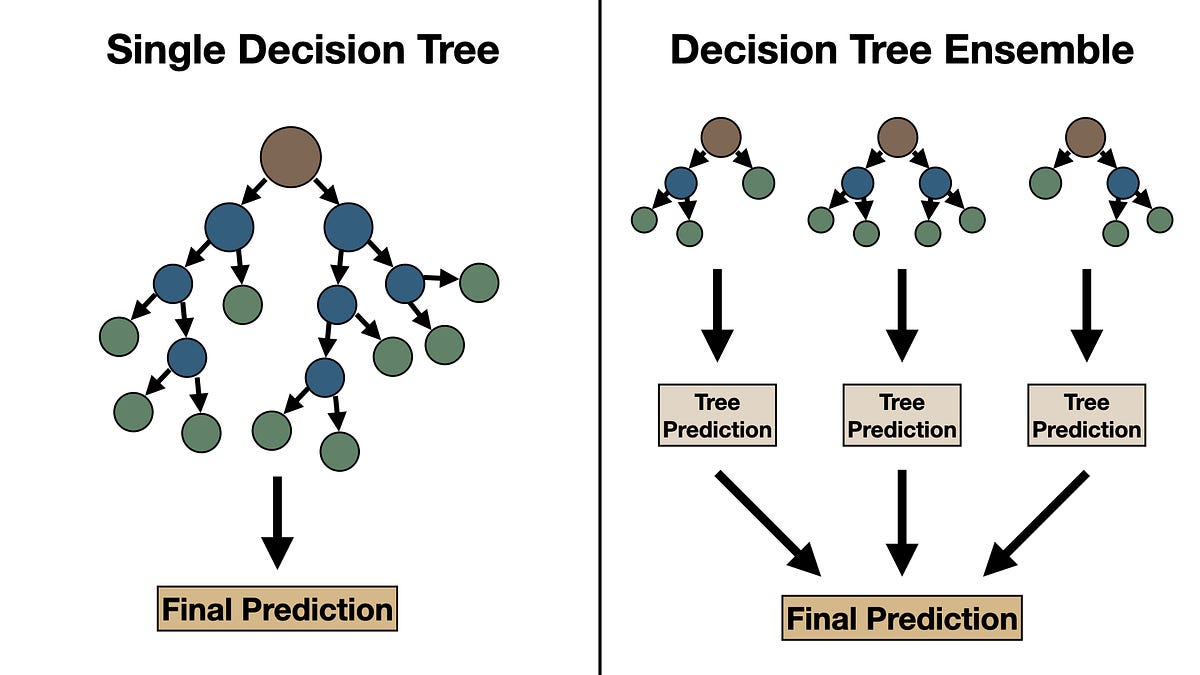
XGBoost is fast to learn, easy to tune, and can supply a ranking of variables, making interpretation of learned models easier . However, there are also some disadvantages to using XGBoost for multivariate VAR modeling. XGBoost's classification effect in the case of data imbalance is often not ideal .
When should you not use XGBoost
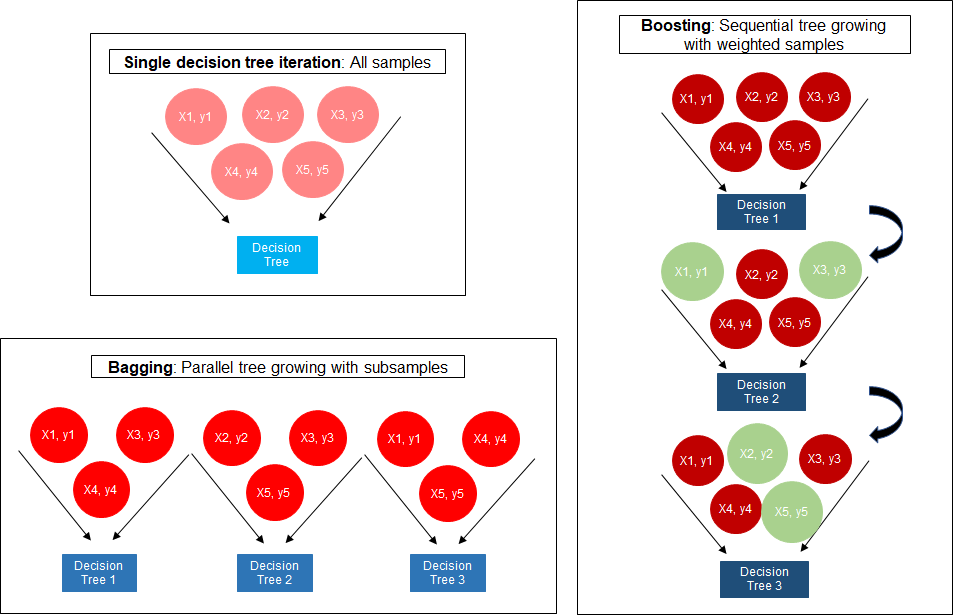
In terms of dataset size problems, XGBoost is not suitable when you have very small training sets ( less than 100 training examples) or when the number of training examples is significantly smaller than the number of features being used for training.XGBoost is a boosting algorithm that uses bagging, which trains multiple decision trees and then combines the results. It allows XGBoost to learn more quickly than other algorithms but also gives it an advantage in situations with many features to consider.Since gradient of the data is considered for each tree, the calculation is faster and the precision is accurate than Random Forest. This makes developers to depend on XGBoost than Random Forest. XGBoost is complex than any other decision tree algorithms.
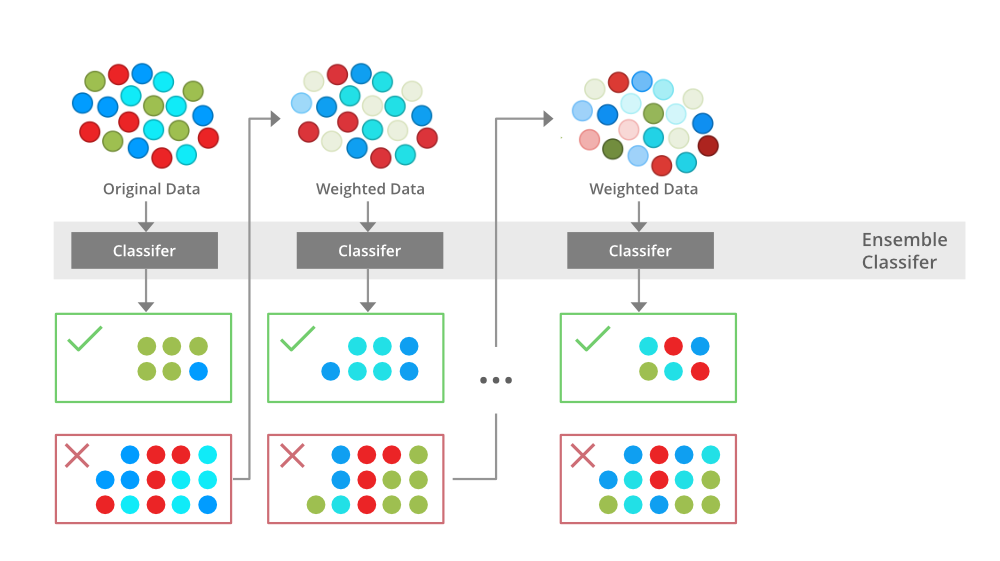
XGBoost can be avoided in following scenarios: Noisy Data: In case of noisy data, boosting models may overfit. In such cases, Random Forest can provide better results than boosting models, as Random Forest models reduce variance. XGBoost, or Tree based algorithms in general, cannot extrapolate.
What are the weaknesses of XGBoost : The XGBoost method is limited to convex loss functions, which may not be suitable for certain applications. Some limitations of XGBoost include being a time-consuming greedy algorithm and the non-necessity of multi-threaded optimization.
What is faster random forest or XGBoost : Though XGBoost is noted for better performance and high speed, these hyperparameters always stop developers from looking into this algorithm. Hyperparameters are not needed in Random Forest and developers can easily understand and visualize Random Forest algorithm with few parameters present in the data.